
全角キーワード
Visual Basicでは、BASIC時代からずっとですが、アルファベットの大文字と小文字を区別しないことは皆さまもご存知かと思われます。
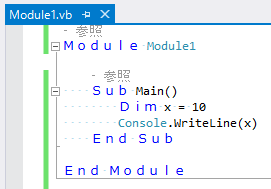
で、実は、大文字小文字だけじゃなくて、半角全角も区別しないという。以下のコード、コンパイルして実行することもできるし、Visual Studio上ではちゃんと、Moduleとかの部分が青色(キーワードの色)で表示されます。
Module Module1
Sub Main()
Dim x = 10
Console.WriteLine(x)
End Sub
End Module
まあ、今のVisual Studio上では、全角文字でキーワードを打つと、自動補完で打ったそばから半角CamelCaseに変換されていくんで、自動補完に直されるたびにCtrl+Zで元に戻したりしないとこのソースコードを作れなかったりはするんですが。
もちろんRoslynでもいまだこの仕様
これ、おそらくは初期のVBで日本人が出した要望を真に受けて実装しちゃったものだと思うんですが…
何が恐ろしいって、その時代にはUnicodeがないこと。Shift_JIS、つまり、日本語ロケールでしか扱えない(後々には韓国語や中国語の文字コードにも全角英数入ってるみたいですけど、最初に作った戦犯は日本のはず?たぶん)文字に対する特殊対応入れさせるとか、当時の日本どれだけわがまま言ってるんだと…
その時代からの名残のコードなのか、現在のRoslynのVBのスキャナー(構文解析で、単語を切り出す部分)には以下のようなコードが含まれています。
Private Const s_fullwidth = CInt(&HFF00L - &H0020L)
REM 中略
Friend Const FULLWIDTH_APOSTROPHE As Char = ChrW(s_fullwidth + AscW("'"c)) REM '
Friend Const FULLWIDTH_QUOTATION_MARK As Char = ChrW(s_fullwidth + AscW(""""c)) REM "
Friend Const FULLWIDTH_DIGIT_ZERO As Char = ChrW(s_fullwidth + AscW("0"c)) REM 0
Friend Const FULLWIDTH_DIGIT_SEVEN As Char = ChrW(s_fullwidth + AscW("7"c)) REM 7
Friend Const FULLWIDTH_DIGIT_NINE As Char = ChrW(s_fullwidth + AscW("9"c)) REM 9
Unicodeが普及した今なら普通にIMEで変換した全角文字で"0"cって書けばいいだけの話なのに… IMEを持っていない国に配慮しても、Unicode エスケープシーケンスで\uFF10とか書ける。それを、わざわざ&HFF00L - &H0020L (全角文字の開始番号 - 半角スペース)を足して作ってるという。
全角リテラル?!
そんなおぞましいコードを見てしまった外国人曰く、
「"x"wみたいに、文字リテラルにw語尾つけて全角文字を作れたら便利じゃない?」
…
…
…
…
おい、バカ、やめろ。
ちなみに、これに対するコメントでの大まかな会話の流れをまとめると、
- 「Wide Char」って言い方が悪く、他の人「UTF16に収まらない文字のこと?可変長バイトだし難しくない?結合文字のせいで大変よ。U+1F469 U+1F3FB U+200D U+2764 U+200D U+1F468 U+1F3FFで、『色白女性と濃い褐色肌男性が愛し合ってる絵文字』という1文字で表示すべきとされてたり」
- 他の人「いや、そうじゃなくて、日中韓で使ってる全角文字のことらしい」
- 他の人「えっ、その手の国だとIME使って全角文字打てるし、全角文字なら16ビットの範囲内だし、それで入力できるんじゃないの?wリテラル作る価値ある?」
- 提案者「日中韓の人なら便利なんじゃないの?たぶん」
おい、バカ、マジでやめろ。
ということで、この流れに気づいた瞬間、「あらゆる意味でそんなものほしくない。全角英数は恐ろしくクソな負の遺産。きっと多くの日本人開発者が憎んでる。」とコメントをつけておきました。
負の遺産怖い…
VB 6以前、あるいはVBAとかVBScriptとかからの習慣なわけで、たぶん20年越しの呪いですよ、これ。しかも、Unicodeがなかった時代に「大文字小文字を区別しないんだったら、全角半角も区別しないべきじゃないか」とか言い出した人がいての結果(のはず。たぶん)。
こんな、(キーワードに全角文字使えるとか)今となっては知ってる人すら減ってるご時世に、特殊対応のためにVBのスキャナーに負担をかけて、全世界の皆様にご迷惑かけて大変申し訳ない気分。
文字のビット数問題
まあ途中の議論で出ていた、.NETのcharで扱えない文字、16ビットに収まらないやつに対する操作は確かにほしかったりはしますが…
.NETで文字列が内部的にUTF16なの、.NETの登場時期(16ビットですべての文字を固定ワード幅表現できるとか夢見ちゃってた時代)を考えると仕方がないんですが、大変不便なので。今や、修飾文字とかあって32ビットですら固定ワードにならず、PowerShellみたいに32ビットで文字列を扱ってもやっぱり解決せず。
むしろ、本当にほしいのは「UTF8をバイト列のまま扱える」クラスと、そこから「1文字とみなされるべき部分を抜き出す」メソッドなのではないかと。
ちなみに、「UTF8をバイト列のまま扱える」クラスは、今、CoreFxチームが試験的に実装中らしいです。試験的リポジトリcorefxlab に、以下のようなクラスが最近追加されました。
- Span: 配列の途中区間やネイティブバッファーに対して、ポインターで(コピーなしで)アクセスするクラス
- Utf8String: Spanを使ってコピーなしで、UTF8バイト列をそのまま文字列処理するためのクラス