
概要
「[雑記] 識別子名に使える文字」 で説明したように、C# では、Unicode の文字クラスに基づいて「使える文字」を規定しています。 ここでは、いくつかその Unicode にまつわる与太話をしていきます。
C# だけでなく、1990年代後半以降にできたプログラミング言語はだいたい同じような方針のはずです。 (ぱっと思いつくのでも、Java, Go, Swift とかではここで話したような内容が当てはまるはず。)
空白文字
識別子だけでなく、空白文字の判定にも Unicode 文字クラスを使います。 (C# の場合、空白文字はほとんどの場面で意味を持たず無視されます。意味があるのは ++ の間くらい。) 具体的には、C# の空白文字の定義は以下のようになっています。
-
空白(whitespace)とは、以下のいずれかである
-
Unicode クラス Zs の任意の文字
-
水平タブ (horizontal tab) 文字 (U+0009)
-
垂直タブ (vertical tab) 文字 (U+000B)
-
改ページ (form feed) 文字 (U+000C)
-
また、クラス Zs の文字は表1に示す通りです。
| 文字コード | 文字 | 補足 |
|---|---|---|
| U+0020 | SPACE | 普通のスペース |
| U+00A0 | NO-BREAK SPACE | 「ここで改行するな」指定付きのスペース |
| U+1680 | OGHAM SPACE MARK | 古アイルランド語の文字 |
| U+2000 | EN QUAD | n 字幅のクワタ(行末の隙間埋めスペース) |
| U+2001 | EM QUAD | m 字幅のクワタ(行末の隙間埋めスペース) |
| U+2002 | EN SPACE | n 字幅のスペース |
| U+2003 | EM SPACE | m 字幅のスペース |
| U+2004 | THREE-PER-EM SPACE | 1/3 m 字幅のスペース |
| U+2005 | FOUR-PER-EM SPACE | 1/4 m 字幅のスペース |
| U+2006 | SIX-PER-EM SPACE | 1/6 m 字幅のスペース |
| U+2007 | FIGURE SPACE | 数字と同じ幅のスペース |
| U+2008 | PUNCTUATION SPACE | ピリオドとかと同じ幅のスペース |
| U+2009 | THIN SPACE | 狭いスペース |
| U+200A | HAIR SPACE | かなり狭いスペース |
| U+202F | NARROW NO-BREAK SPACE | 細めの「ここで改行するな」指定付きのスペース |
| U+205F | MEDIUM MATHEMATICAL SPACE | 数式中で記号間に使うスペース |
| U+3000 | IDEOGRAPHIC SPACE | 日本語の全角スペース |
幅違いなだけのスペースが山ほどあります。例えば、m 字幅、n 字幅を | で囲って表示してみると、図1のようになります。 (ちなみに、Microsoft Word で Unicode を16進数で打った後、Alt+X を押すと変換できたりします。この場合はそれぞれ 2000, 2001, 2002, 2003 の後に Alt+X。)
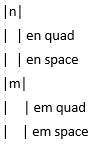
表1の最後の1列を見ての通り、全角スペースも Zs クラスです。 つまり、C# は全角スペースをちゃんと空白文字として認識しています。 「プログラマに全角スペースを見せると発狂する」なんてネタもありますが、ソースコードを Unicode で保存する限り、全角スペースが入っていてもどうということはありません。

ちなみに、Visual Studio は Zs クラスの文字を打った先から消したり、通常のスペース(U+0020)に変換したりしてくれますが、 クリップボードから貼り付けた上で、Visual Studio に変換されてしまったら Ctrl+Z で戻すとかやれば、 任意の空白文字を入力することは一応できます。 メリットはないですけども。
注意: カタカナ中点
Unicode の文字クラスに基づいているということは、Unicode に変更があった場合、C# も影響を受けます。 日本語的にかなり困るのは、カタカナ中点(なかぐろ)「・」(katakana middle dot、U+30FB)です。
カタカナ中点は、昔は Pc クラス(connector。C# 的には識別子の2文字目以降に使っていい文字)でしたが、 Unicode 5.1 から 6.0 の間で Po クラス(その他の句読点。C# 的に、識別子に使えない)に変更されました。 ちなみに、カタカナ中点の用途はハイフンとかと同じということになっているので、Po が正しい(ハイフンとかは Po)です。 5.1 までがミスみたい。
そして、C# 6 から、判定基準が Unicode 6.0 以降になりました。 つまり、以下のソースコードは、C# 5.0 まではコンパイルできたものの、C# 6 ではコンパイルできません。
using System;
class Program
{
static void Main(string[] args)
{
int x・y = 10;
Console.WriteLine(x・y);
}
}
同様の問題は、Java 7 でも起きているようです。
余談: Visual BasicとUnicode
余談になりますが、使っているUnicodeのバージョンが変わった影響は、Visual Basicの方が大きいみたいです。
VBは、識別子の大文字・小文字を区別しない言語なわけですが、この大文字・小文字の判定もUnicodeの文字クラスをベースに判定しています。
カタカナ中点のように文字クラスががらっと変わったような文字はほとんどありませんが、大文字・小文字の判定変わった文字はちらほらあるみたいで、VBに影響が少し出ているそうです。 (こちらは、日本人にとっては全くといっていいほど影響はないはずですが。)
絵文字
Swift は絵文字を識別子に使えると聞いて。
ちなみに、C#は今のところ、サロゲート ペア (16ビットで収まらず、UTF16 では2ワードになっちゃう文字)になっている文字は受け付けていません。 絵文字はその領域に入っている文字なので、識別子には使えません。
また、たとえC#がサロゲート ペアを解釈するようになったとしても、絵文字はUnicodeの文字クラスは「記号・その他」(C#では識別子に使えない)なので、C#で絵文字識別子が使えるようになることは今後もないでしょう。
まあ、使えてもしょうがないというか、むしろ使えるとやばそうな例がいくつかあったりします。
カラー絵文字
やばい例その1: http://www.swiftstub.com/381749597/
let 💙 = 1
let 💚 = 2
let 💛 = 4
let 💜 = 8
println(💙 + 💚 + 💛 + 💜)
15
上から順に、青ハート、緑ハート、黄ハート、紫ハートです。カラー絵文字フォントを使って表示すると結構きれい。 白黒フォントだと結構悲惨。
数学シンボル
やばい例その2: http://www.swiftstub.com/647829248/
let 𝟢 = 1
let 𝟣 = 2
let 𝟤 = 4
let 𝟥 = 8
let 𝟦 = 16
let 𝟧 = 32
let 𝟨 = 64
let 𝟩 = 128
let 𝟪 = 256
let 𝟫 = 512
var x = 0
x += 𝟢
x += 𝟣
x += 𝟤
x += 𝟥
x += 𝟦
x += 𝟧
x += 𝟨
x += 𝟩
x += 𝟪
x += 𝟫
println(x)
1023
コンパイル通った… 𝟢って書いたら0じゃなかった。 何を言っているかわからねぇと思うが、書いた本人も後で見てわかる気がしねぇ。
種を明かすと、これ、変数に使っているのは数学シンボルです。 「Mathematical Alphanumeric Symbols」って言って、U+1D400 ~ 1D7FF の辺りに、数式で使う用の、フォント指定付きのアルファベットや数字があります。 上記コードの0は、リテラルの方が普通の数字、変数に使ってる方が「MATHEMATICAL SANS-SERIF DIGIT」(サンセリフ フォント指定の数字)の𝟢(U+1D7E2)。
ちなみに、Unicode 的にも、こういう「フォント指定付き文字」みたいなものを使うのはあんまり推奨されていません。