
ジェネリックの実現方法
ジェネリックの実装方法はプログラミング言語ごとに方針の差が結構あります。例えば、以下のようなやり方があります。
- 全展開(C++など)
- 値型のみ展開(C#など)
- 型消去(Javaなど)
例えば、以下のようなコードを書いたとします。単純なジェネリック クラスと、その利用側コードです。
public class Wrapper<T>
{
public T Value;
}
class Program
{
static void Main(string[] args)
{
var i = new Wrapper<int> { Value = 1 };
var b = new Wrapper<byte> { Value = 1 };
var s = new Wrapper<string> { Value = "abc" };
var a = new Wrapper<int[]> { Value = new[] { 1, 2, 3 } };
int iv = i.Value;
byte bv = b.Value;
string sv = s.Value;
int[] av = a.Value;
}
}
4つの型パラメーターを使っていて、そのうち、2つ(intとbyte)は値型、残り2つ(stringとint[])は参照型です。
これが、どういう風に展開されるかを見ていきましょう。
全展開(C++など)
わかりやすい実装は、型パラメーターごとにすべて展開してしまう手法(全展開)です。 C++ではこの手法でジェネリックを実現しています。 (ちなみに、C++の言語機能としてはテンプレート(template)と呼びます。 コンパイル時に全部ひな形生成してしまう辺りが「テンプレート」(ひな形、鋳型)と呼ばれる所以です。)
先ほどのコードを「全展開」で実装すると、以下のようなものに相当するコードが生成されます。
// 使った分だけそれぞれ別の型に展開
public class Wrapper_int { public int Value; }
public class Wrapper_byte { public byte Value; }
public class Wrapper_string { public string Value; }
public class Wrapper_Array_int { public int[] Value; }
class Program
{
static void Main(string[] args)
{
var i = new Wrapper_int { Value = 1 };
var b = new Wrapper_byte { Value = 1 };
var s = new Wrapper_string { Value = "abc" };
var a = new Wrapper_Array_int { Value = new[] { 1, 2, 3 } };
// キャストは不要
int iv = i.Value;
byte bv = b.Value;
string sv = s.Value;
int[] av = a.Value;
}
}
このコードは、以下のようなメモリの使い方をします。
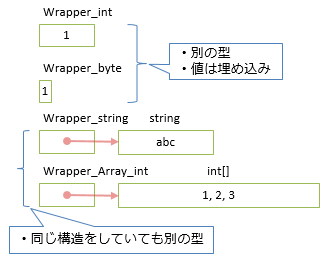
利点
- 無駄なオーバーヘッドがなくなって、実行性能がいい
欠点
- 型パラメーターに与える型が増えると、生成されるプログラムのサイズが大きくなりすぎる
型消去(Javaなど)
全展開の真逆の実装は、全部の型を消してしまう手法(型消去)です。
object型にはどんな型でも代入できるので、object型なクラス1つを用意して、適宜キャストを挟むコードを生成します。
Javaではこの手法でジェネリックを実現しています。
先ほどのコードを「型消去」で実装すると、以下のようなものに相当するコードが生成されます。
// object 型な1つのクラスに集約
// 元の型情報を残さない = 型消去
public class Wrapper { public object Value; }
class Program
{
static void Main(string[] args)
{
var i = new Wrapper { Value = new Integer(1) };
var b = new Wrapper { Value = new Byte(1) };
var s = new Wrapper { Value = "abc" };
var a = new Wrapper { Value = new[] { 1, 2, 3 } };
// キャストが必要
int iv = ((Integer)i.Value).Value;
byte bv = ((Byte)i.Value).Value;
string sv = (string)s.Value;
int[] av = (int[])a.Value;
}
}
//↓こんな感じのクラスが標準ライブラリ中にある
public class Integer
{
public int Value;
public Integer(int value) { Value = value; }
}
public class Byte
{
public byte Value;
public Byte(byte value) { Value = value; }
}
このコードは、以下のようなメモリの使い方をします。
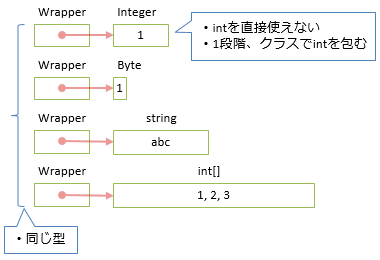
利点
- 実装がシンプル
欠点
-
実行性能的に不利
- 特に値型に対してボックス化が発生するのがかなりつらい
値型だけ展開
C#の実装は全展開と型消去の間くらいの手法になっています。
型消去の場合、値型に対してボックス化が起きることが実行性能上かなり不利になります。 そこで、C#の実装では、値型だけは展開し、参照型に対しては型消去に近いコードを生成します。
要するに、先ほどのコードから、以下のようなものに相当するコードが生成されます。
// 値型の場合: 使った分だけそれぞれ別の型に展開
public class Wrapper_int { public int Value; }
public class Wrapper_byte { public byte Value; }
// 参照型の場合、object 型な1つのクラスに集約
public class Wrapper { public object Value; }
class Program
{
static void Main(string[] args)
{
var i = new Wrapper_int { Value = 1 };
var b = new Wrapper_byte { Value = 1 };
var s = new Wrapper { Value = "abc" };
var a = new Wrapper { Value = new[] { 1, 2, 3 } };
// 値型はキャスト不要
int iv = i.Value;
byte bv = b.Value;
// 参照型
// (C#(.NET) の場合はこのキャストを取り除くような最適化もしてる)
string sv = (string)s.Value;
int[] av = (int[])a.Value;
}
}
このコードは、以下のようなメモリの使い方をします。
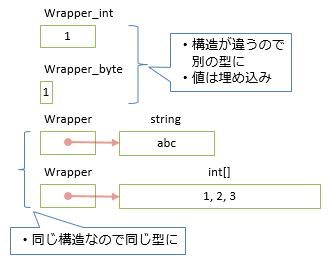
利点
- プログラム サイズの増大と実行性能のバランスがいい
欠点
-
コンパイラーの実装が大変
- 機能の修正がしにくい