
今日もC# 8.0の新機能の話で、今日のはすでに Visual Studio 2019 Preview 1に入っているやつです。
Ranges and Indicesと呼ばれていて、配列などに対して、
a[^i]で「後ろからi番目」とか、
a[i..j]で「i番目からj番目の範囲」とかを取り出せるようにする機能です。
正確にいうと、^iとかi..jとかの部分がC#の新機能で、
これらはそれぞれIndex型、Range型になります。
Index、Rangeを受け取るインデクサーやメソッドはライブラリ側の機能です。
(ただし、配列だけは言語レベルで処理している模様。)
背景1: 統一ルールが欲しい
一旦先ほどの説明は忘れてまっさらな状態で、 例えば「3..5」と言われると何を思い浮かべるでしょう。 文脈次第だとは思いますが、以下のようなものがあり得ます。
- 3, 4, 5 (5も含む)
- 3, 4 (5は含まない)
- 3, 4, 5, 6, 7 (3から初めて5つ)
どれがいいかは用途次第で、実際、どれもあり得ます。 例えば、.NET でも、以下のようなメソッドがあります。
var r = new Random();
var a = new[] { 0, 1, 2, 3, 4, 5, 6, 7, 8 };
var x = r.Next(3, 5); // 3, 4 (5を含まない)
var s = a.AsSpan(3, 5); // 3, 4, 5, 6, 7 (3から始めて5つ)
ちょっとでもわかりやすくしたければ、以下のように名前付き引数にすべきかもしれません。
var x = r.Next(minValue: 3, maxValue: 5); // 「5つ」でないことは明確なものの、5を含むかどうかわからず
var s = a.AsSpan(start: 3, length: 5); // これなら割とわかりやすく「3から始めて5つ」
Random.Nextの例のように、名前が「max」だけで、「含むかどうか」がわからないAPIも多いです。
この区別のために、Parallel.Forなんかは引数名がfromInclusive、toExclusiveとかになっていたりします。
しかし、どんどん名前が長くなって書きづらい上に、
所詮は命名規約なので規約が守られない場合だってあり得ます。
さらにいうと、多次元データになるともっとしんどくなります。
var m = new[,]
{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 },
};
// (x, y) が (1, 2) ~ (3, 4) の範囲?
// x が 1~2、y が 3~4 の範囲?
// 2, 4 は含む?含まない?
var n = m.Slice(1, 2, 3, 4);
ということで、範囲を表す専用の文法が欲しいという話になります。
背景2: インデックス用途
その両端を含むか含まないか問題ですが、どちらがいいかは正直用途によります。
例えば、x in 1..3 みたいに「x がその範囲に入るかどうか」(マッチング用途)の場合、
大体は「3も含む」の方にしたいという要望が多いです。
一方で、x[1..3]みたいに「xの1番から3番の要素」(インデックス用途)の場合、
「3を含まない」にした方が都合がよかったりします。
インデックス用途における「含まない」の利点は以下のようなもの。
-
実装上、パフォーマンス的に有利
- 長さを
length = maxExclusive - minInclusiveで計算できる(+1が要らない) - ループが
for (var i = minInclusive; i < maxExclusive; i++)になる(<=だとint.MaxValueに対する特別扱いが必要)
- 長さを
i..iが空(0要素)範囲になる。「含む」の方だと空範囲がi..i-1になってちょっとキモい
C# 8.0で導入される範囲構文は、後者のインデックス用途を狙ったもので、「末尾は含まない」の方になります。
ちなみに、「範囲に入るかどうか」の方は別途パターン マッチングの一種(range pattern)として提供される可能性はあるんですが、
おそらく別の文法(x in 1 to 3みたいな)になりそうです。
一方、インデックス用途に絞ったことで、
「配列の末尾からi番目」を表したいという別の要望も出てきます。
そこで、^演算子を導入して、^iで「末尾からi番目」を表すことになりました。
文法
ということで、C# 8.0で導入されるのは以下のような文法です。
-
^i演算子で「末尾からi番目」を表すIndex型を作る- 正確には「
Length - i」を表す。^0はLength番目なので、array[^0]は OutOfRange。
- 正確には「
-
i..j演算子で、「i番目からj番目」を表すRange型を作る- 開始の方(
i)は含む、末尾の方(j)は含まない - 両端は省略可能。
i..なら「iから末尾」、..jなら「先頭からj」、..なら「配列全体」 Indexを受け付ける。^3..なら「末尾から3要素」
- 開始の方(
ちなみに、Range、IndexはいずれもSystem名前空間の構造体です。
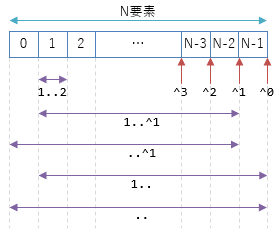
例えば以下のように書けます。
var data = new[] { 0, 1, 2, 3, 4, 5 };
// 1~2要素目。2 は exclusive。なので、表示されるのは 1 だけ。
Write(data[1..2]);
// 先頭から1~末尾から1。 1, 2, 3, 4
Write(data[1..^1]);
// 先頭~末尾から1。 0, 1, 2, 3, 4
Write(data[..^1]);
// 先頭から1~末尾。 1, 2, 3, 4, 5
Write(data[1..]);
// 全体。0, 1, 2, 3, 4, 5
Write(data[..]);
内部実装
実装としては以下のようになります。
^iはnew Index(i, true)になる(第2引数のtrueが「末尾から」の意味)- 整数から
Indexへは暗黙の型変換がある i..jはRange.Create(i, j)になるi..はRange.FromStart(i)になる..jはRange.ToEnd(j)になる..はRange.All()になる
var r1 = Range.Create(1, 2); // 1..2
var r2 = Range.Create(1, new Index(1, true)); // 1..^1
var r3 = Range.ToEnd(new Index(1, true)); // ..^1
var r4 = Range.FromStart(1); // 1..
var r5 = Range.All(); // ..
ちなみに、Range、Indexはそれぞれ、
-
Index…intを1つだけ持つ構造体- .NET の配列は負のインデックスを想定していないので、負の数を使って「末尾から」を表現
Range…Indexを2つ持つ構造体
になっています。
また、構文上は、^の方は単なる単項演算子、
..の方は専用の構文(オペランドを省略可能というのが特殊なので、単なる2項演算子扱いにはできない)だそうです。
Rangeを受け付けるインデクサー
配列に対して a[i..j] と書いた時の挙動はちょっとまだもめているみたいです。
要は以下のどちらにすべきか。
-
配列からは配列で「subarray」を返すべきではないか
- 新しい配列のアロケーションとコピーが発生
- アロケーションを避けるために
Span<T>で返すべきではないか
Visual Studio 2019 Preview 1 での実装は前者になっていて、
new T[]とArray.Copyが生成されます。
パフォーマンスを気にするならa.AsSpan()[i..j]と書く必要があります。